How AI-based data augmentation helps to simplify the development of AD algorithms
Bosch Research Blog | Post by Thomas Michalke, 2021-05-18


Affordable automated driving functions for everybody
Automated Driving (AD) might be the next big disruptive game changer to affect our everyday lives. Imagine calling your ride with your smartphone in the morning. A driverless, comfortably warm limousine enters your driveway exactly in the second forecasted by your smartphone. You take the back seat, take out your laptop and start working while you are driven to work. Will you need to own a personal vehicle anymore?
Well, there is still a long way to go until we release a technology that works in all weather conditions and for unknown corner cases that may occur in an open-world context. So far, first prototypes and small to medium scale non-profit and geographically restricted research experiments are running. Mainly in the background of public awareness, we at Bosch are working on the required technology on all system levels to turn this vision into reality in large-scale products available for everybody (e.g. RADAR, LIDAR and video sensors, intelligent vehicle computers, fail-safe electric steering systems). On the way to fully-automated driving in a sense of an automated taxi, there are multiple intermediate steps using a subset of the technology that will improve and ease our everyday driving experience. So this is not a distant vision – there are exciting products available already today!
Automation levels: Fully automated versus partial and conditional ?
The aforementioned future fully-automated taxis belong to automation “level 4” and beyond, which means no human is required for supervising the vehicle and its actions within its defined scope of application. The system is able to resolve all situations within that scope on its own. Among other things, automation level 4 requires a high level of redundancy in all system-critical hardware parts (sensors, computation resources, actuators) as well as a software design with redundant paths to fulfill extremely challenging safety goals.
In contrast, AD systems that offer an automation level between level 2 (partially automated) and 3 (conditional automated) still have the human component as a fallback layer. Level 2 automation means that a driver always has to supervise the system and be able to take over at any given moment and without any delay. For example, there are mono-camera-based lane keep systems that support the driver to stay in the lane and radar-based systems that keep the distance to the preceding vehicle, known as adaptive cruise control (ACC). A level-3 system allows the driver to be out of the loop and lean back in certain defined situations. But the human driver is still involved and he has to take over within seconds whenever the AD system is unable to cope with a situation and issues a take-over request. For example, a traffic jam pilot is a level-3 system for which a detailed regulation exists since mid-2020. Level-2 and level-3 automation already allows for extremely fascinating products that are suitable even for price-sensitive standard vehicles and allow for safer and more comfortable driving.
In this blog article, we will look deeper into safety and comfort aspects of AD systems that are suitable to the volume vehicle segment. Exemplarily focus will be placed on mono-video cameras as one cost-efficient solution to mass-market AD.
The potential of mono-video cameras for automated driving applications
All sensor modalities, e.g. RADAR or mono video cameras, are beneficial for both domains – safety and comfort. With a focus on the influence of specific AD functions on driving safety, a closer look on the NCAP assessment is beneficial. For example, the NCAP decided to award stars for active safety to vehicles with a lane-keeping system as well as a system that is able to detect speed-limiting traffic signs. Warning the driver in case of speeding and active speed control is also awarded by NCAP, all driven by statistically sound accident research analyses. The functions referenced by NCAP can be realized with different sensor modalities or their combinations. The use of video cameras is one suitable approach for realizing the aforementioned AD applications.
In addition to these safety-related functions, a video sensor can be used for enhancing the driving comfort as well.
For example, a recent Bosch Research project was able to demonstrate that adaptive cruise control (ACC) is also feasible with a single mono-video camera. Unlike with a RADAR sensor, the two major quantities – object distance and relative velocity – as mandatory inputs for an ACC speed control cannot be measured directly from the raw video data. To compensate for these shortcomings of mono-video cameras, smart vision algorithms have been developed: The object distance can be robustly estimated e.g. by using structure from motion (two images recorded consecutively in time provide two dimensions that can be used to reconstruct the missing third dimension, i.e. the distance information). The object velocity can be determined by tracking the derivative of the distance value as well as by evaluating the optical flow.
All in all, a video camera has the potential to deliver important features for automated lateral (steering) and longitudinal (braking, accelerating) control and is able to robustly resolve the most general scenarios such as “stay in the lane” and “comfortably follow the car in front”. In combination with a RADAR sensor, the level of driving comfort is further improved, e.g. by using the increased object detection performance and range to enhance the system availability towards higher vehicle velocities.
After this rather general introduction into the capabilities of some AD sensor modalities, we will take a deeper look into current research approaches that squeeze as much functionality as possible out of a mono-video camera, leading to an increased system availability even in challenging scenarios. Again, the presented concepts are not restricted to video sensors, but can be applied to any other sensor modality as well.

Challenges: Situational analysis in complex cut-in scenario
One very challenging and potentially critical scenario on highways is a truck or another vehicle cutting in the ego vehicle lane without much lead time. A classic ACC system will start to react when the cutting-in vehicle is detected as driving in the same lane as the ego vehicle. This means that the reaction is delayed until a certain fraction of the cutting-in vehicle is inside the ego lane. Depending on the relative distance and velocity, a highly critical situation can occur. Especially trucks tend to show this merge behavior, forcing human drivers to react immediately to prevent the collision. The challenge for e.g. a video-only system is now to react in a predictive way to cutting-in vehicles. So, when the preceding vehicle’s intention to change lanes is detected early enough, the system could react early and in a cooperative fashion, e.g. by predictively opening a gap. In other words, the focus is on detecting these cut-in lane-change situations before they actually happen.
A lane-change decision typically depends on numerous factors. It might be strongly influenced by a combination of weak and often poorly observable factors, e.g. the local density or behavior of the surrounding traffic. AI approaches help to determine and combine the decision-relevant factors. In order to solve this challenging prediction task, we proposed different neural network architectures relying on supervised learning and evaluated these offline and online in a test vehicle. The special technological challenge is that the training dataset is small and imbalanced, which means we needed to apply specific, alleviating data augmentation measures during training. The data set is (and was selected deliberately) small, because critical lane-change scenarios tend to be rare – hence collecting a sufficient amount of data is expensive.

A small amount of data is always a problem for neuronal networks in the domain of supervised and unsupervised learning, because the networks overly adapt to the training data. During inference on new data, a large performance gap between the training and the (online) application is experienced. In our example, when applying the network trained without alleviating measures in our test vehicle, the predictive detection capability is much worse than the receiver operating characteristic curve during offline training and test would suggest.
A machine-learning solution that automatically provides test data
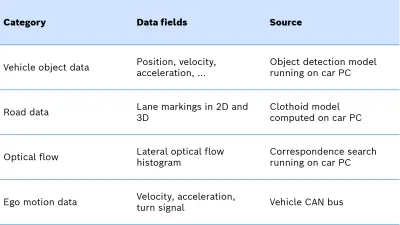
After a thorough analysis, we came up with three different network architectures (a Long Short-Term Memory architecture and two Convolutional Neuronal Network architectures, see Figure 1). All three use the aggregated (i.e. non-raw) object data shown in Table 1 as input. We additionally experimented with different approaches to tackle the problem of small datasets and to avoid overfitting. In addition to classical data augmentation techniques such as adding noise or shuffling/mirroring the input data, we also applied a Variational Autoencoder (VAE) and a simulation framework, both for generating synthetic input data based on the real small input data set as a basis. Especially the VAE is a highly interesting concept, because it is able to generate an large amount of new arbitrary data, given a learnt abstraction of a (small) dataset. Put simply, its structural architecture has some similarity to an hourglass. First, there is an encoder step, followed by a decoder step. In the encoder step, the dimensionality of the input data is greatly reduced.
This compact representation is called latent space, which can be understood as a highly aggregated, abstract representation of the input data. In this latent space, we add random noise, after which the decoder step scales up the data to the dimensionality of the input data. This approach is very similar to the well-known computer-generated deep dreaming images, but applied on aggregated time series data instead of images. Based on added noise, the VAE is dreaming an arbitrarily large amount of additional new data, which can be used for data augmentation and hence improved training.
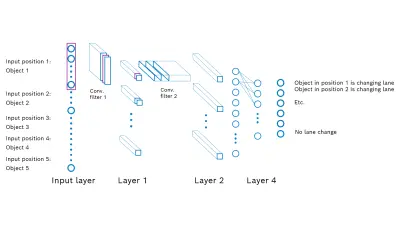
Finally, we compared the three networks with the aforementioned different techniques for alleviating the problem of small datasets and did online evaluations driving in the open world with our test vehicle. We were able to predict many lane changes correctly. The approach worked out well for a proof-of-concept research system. Still, from our point of view, the problem of small datasets cannot be fully resolved, but at least alleviated with this technique. This means performant data-driven detectors can be realized even in case of small datasets. This in turn improves the product quality and customer benefit without additional cost.
Summary
This blog has highlighted two highly interesting AI applications in the context of machine learning: (1) Determining the lane-change probability of vehicles cutting in in front given the full environment model and context information of a scenario and (2) a Variational Autoencoder as a means for data augmentation given small datasets to improve the product quality without additional costs. Both AI approaches have been evaluated in an online mono-video level-2 system. An application in a multi-modal level 3+-system could be beneficial as well. Given the extended requirements in system robustness, here the role of approach (1) could be to provide an additional redundant processing path e.g. for situation analysis. With approach (2), a performance boost of all data-driven detectors is achieved. As shown, AI can improve the driving experience of end customers in manifold ways, enabling Bosch products invented for life.
What are your thoughts on this topic?
Please feel free to share them or to contact me directly.
Author: Thomas Michalke
As a systems engineer, Thomas has been working on the challenging task of automated driving for 15 years. At Bosch Research, he leads a project team that is working on automated driving for dense real-world traffic. As an example, they answer the question of how automated vehicles need to act in order to force a gap when driving onto a motorway in heavy traffic.


