Why you need to leverage hardware assisted regulation mechanisms
Bosch Research Blog | Post by Dakshina Dasari, Arne Hamann, Falk Rehm, 2021-02-11


Imagine that you wake up and find you are a system integrator who is assembling the “vehicle computer” of the future – you have a powerful heterogeneous System-on-Chip (SoC) at your disposal that serves as the integration platform, and this SoC features clusters of general-purpose cores, GPUs, other accelerators, more than sufficient memory – in short, tremendous power packed on a single chip. You are given a diverse set of well-tested applications, developed by different vendors, with different Quality of Service (QoS) requirements, e.g. some having stringent real-time requirements, as well as different safety criticality levels. Your job is to deploy this mix of applications together on the vehicle computer and to ensure that all applications behave as they did when running in their silo set-ups. Straightforward, one might say, these are pre-tested applications and there is enough computing power! So you cautiously deploy it all together on the most appropriate compute units and get the system rolling, expecting everything to work seamlessly and efficiently. Instead, all hell breaks loose! Your time-critical applications miss their deadlines on your new integration platform and perform worse than they did in their own setups. So what went wrong under the hood? What can you do to ensure that your time-critical applications get all the resources they need to meet their requirements?
Modern SoCs pose new challenges for predictability
Understanding the interactions between hardware and software has always been key for building efficient and predictable systems– with the enormous complexity and potential that modern heterogeneous SoCs offer, the need for this has only become stronger and more urgent than ever. Heterogeneous SoCs appear to be the ideal candidates for integration platforms, since they are inherently designed to host diverse workloads.
However, if we look further, reconciling performance and predictability on these platforms is not straightforward. This stems from the fact that the design of these platforms is geared towards optimizing average throughput, power and cost, and not for predictability. As a consequence, as seen in Figure 1, most platforms feature a setup with multiple cores sharing the last-level cache as well as different computing units, like the general-purpose processing core clusters, graphic processors and other display controllers sharing the same main memory, over a common set of interconnects.
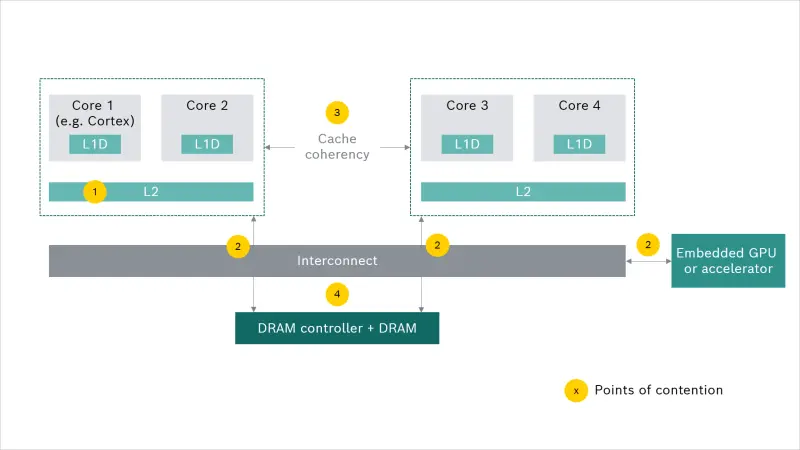
Shared hardware resources – a necessary evil?
The presence of shared resources introduces a strong correlation between the execution of a program and the access to the data it manipulates, as well as a high degree of interference imposing a strong timing correlation between concurrently running applications on the same chip. These effects can be drastic. For instance, it was shown that on the Nvidia Tegra X1 SoC, the average read latency per word in a sequential read scenario from a single core (in isolation) is below 10 ns, whereas it increases to more than 50 ns when simultaneous memory accesses from three other cores are interfering. (Read more about memory interference characterization between CPU cores and integrated GPUs in mixed-criticality platforms).
This demonstrates that the execution time of an application can vary significantly depending on its memory access patterns and execution context. The presence of shared resources has also been known to be a major impediment in designing predictable systems which rely on the tenets of temporal isolation and freedom from interference. In simple terms, the underlying platforms should have features/mechanisms that minimize the variability of execution time of an application and keep the application behavior predictable and independent of other co-running applications in the system.
However, this is not the case: Most of the above shared resources are governed by throughput-oriented arbiters and are agnostic to the criticality and importance of applications and requests executing on the cores. This leads to scenarios in which time-critical applications may suffer performance degradation. For example, with shared caches, the cache lines of a time-critical application running on one core may be evicted by another co-running application on another core. Therefore, depending on the memory access patterns of the co-running applications, the execution time of a candidate application can vary largely.
Similarly, at the DRAM level, computing the memory access latency of a request is non-trivial. Most memory controllers employ the open-page policy with the goal of optimizing the average performance by exploiting row-locality among memory requests. This is achieved by speculatively keeping activated rows open after memory accesses, hoping that the following requests to the banks target the same rows, thereby eliminating the latency and power overhead of activating and pre-charging the banks . The memory request scheduler also reorders requests, preferring requests that target an open row in a bank. Although this is efficient, it leads to non-predictability. With such a policy, it is likely that time-critical tasks may suffer performance degradation, since their memory requests are served after requests from non-critical tasks. Furthermore, there is competition among different memory masters at the interconnect level – the general purpose cores, GPUs, the DMAs, other accelerators for this shared interconnect – and without the ability to prioritize and regulating the traffic issued by the different memory masters, it is impossible to ensure QoS for important applications.
We clearly need regulation mechanisms at the hardware level in order to control this context-dependent execution-time variability to guarantee predictable behavior of time-critical applications. Software-based mechanisms like dynamic cache-coloring do exist, but only address part of the problem and have not yet gained traction in production systems.
Leveraging hardware-assisted profiling and regulation mechanisms
Modern heterogeneous SoCs are increasingly offering regulation knobs that can help to design mechanisms to facilitate temporal isolation and freedom from interference.
For instance, hardware performance counters are offered by most modern processors, enabling system designers to live-instrument micro-architectural events such as cache misses, bus cycles, write stalls, branch mispredictions, etc. These counters can be leveraged to debug performance bottlenecks and to understand the behavior of applications. Furthermore, they can be used to develop regulation mechanisms at the OS or hypervisor level. One prominent example for this is MemGuard, a mechanism to monitor and regulate memory bandwidth at core level.
Chip vendors also provide QoS mechanisms at the interconnect level to shape the memory traffic issued by different memory masters such as the cores and GPUs. For example, ARM SoCs allow to regulate parameters like the number of outstanding transactions and the average transaction rate at the interconnect level for each of the masters.
These regulation knobs at the interconnect level can be used to ensure that no single master monopolizes access to the memory and dynamically reprogram the relevant registers to attain the desired level of QoS for time-critical applications.
Future platforms like Arm DynamIQ will also provide hardware-assisted dynamic cache partitioning mechanisms, allowing applications to have a virtual dedicated cache, helping to alleviate the problems of the shared cache. Also of interest is the Memory Partitioning and Monitoring (MPAM), a hardware specification for distributing and monitoring resources of the memory subsystem to meet QoS requirements of applications. With this, we can look forward to features like memory transactions being tagged with indicators, enabling traffic prioritization among different masters.
Summary and Outlook
Building predictable systems is a hardware-software co-design problem. Software mechanisms that enforce predictability at the application and middleware levels must be complemented with mechanisms at the OS/hypervisor level, which leverage hardware regulation mechanisms to provide the desired QoS to different applications. Considerations regarding the impact of the chosen hardware platform on the performance and predictability have traditionally been an afterthought in the software design process – and this mindset needs to change. We have to acknowledge that no amount of software tuning can alleviate the problems posed by the underlying hardware. Constructive mechanisms to build predictable systems must be adopted right from the inception of the development process and cannot be retrofitted in the later stages.
What are your thoughts on this topic?
Please feel free to share them via LinkedIn or to contact us directly.
Author: Dakshina Dasari
Dakshina is a Research Engineer in the “Dynamic Distributed Systems” group. In this role, she works on designing solutions to enable applications to meet their quality of service requirements when deployed on computing platforms. Her job is particularly interesting since it lies at the conjunction of different disciplines, including cyber-physical systems, high-performance computing architectures and real-time scheduling theory. Her focus lies on designing and evaluating innovative methods and mechanisms for resource management which are correct by construction, formally sound and help in efficiently utilizing the underlying platforms, while also adhering to the application-specific constraints.

Author: Arne Hamann
Arne Hamann is Chief Expert for the development of distributed intelligent systems. Like the Bosch product portfolio, the range of his activities is very broad, encompassing complex embedded systems, where the interaction between physical processes, hardware and software plays a major role, through to IoT systems with elements of (edge) cloud computing.

Author: Falk Rehm
Falk is a Research Engineer in the “Hardware Platforms and Technology” group at Bosch Research. One of his main research interests are mixed-criticality high-performance embedded systems, which are currently deployed as central computing hubs in automotive systems. The goal is to design dynamic resource allocation mechanisms that provide the desired QoS guarantees (such as real-time) to mixed criticality applications while also utilizing the underlying system efficiently.


