AI-Empowered Audio Analytics
Bosch Research Blog | Post by Shabnam Ghaffarzadegan, 2022-02-07


How to empower AI to make sense of environmental sounds
Car horn, baby crying or shouting – easy to categorize those kinds of sound, isn’t it? Well for you and me it is. But what about machines?
Developing a machine listening system like the human hearing to make sense of sounds is one of the growing areas of research. Humans can understand ambiguous and over-lapping sounds and categorizing them into abstract concepts. For example, humans can distinguish shouting and baby crying and categorize them as human sound. They can also recognize car horns or sirens passing by and categorize them as street sound. Is it possible to teach machines to understand these audio cues as we humans do?

The SoundSee team and I at Bosch Research are developing robust and scalable AI-empowered deep audio analytics solutions to extract useful information out of sound patterns for different usecases such as automotive, healthcare, I4.0 and physical security. For example, one of the recent SoundSee projects is pediatric Asthma monitoring. As respiratory illnesses such as asthma and more recently COVID-19 are surging around the world and affecting many lives, Bosch SoundSee team has decided to tap into analyzing physiological sounds – possibly beyond human ear capabilities, including infra/ultra-sonic ranges. The goal of this project is developing AI based models to identify sound anomalies occurring in breathing or speech to identify and monitor asthmatic condition. Here is the link to the project press release during CES 2022.
Like detecting physiological events based on body sound, the SoundSee team can also make sense of street noise to develop audio based smart traffic monitoring solution. The goal of this project is creating a noise map of traffic conditions with information such as: number of pass-by vehicles, vehicle type, direction, speed, etc. The audio-based traffic monitoring solution can be used as a stand-alone device/service or complimentary part to the existing sensors in the street such as camera and inductive loop.
As deep learning approaches have been proven successful in Audio Analytics tasks, we incorporate these solutions along with the traditional machine learning and audio signal processing methods. One of the main challenges of deep learning based approaches is their need to large amount of labeled data. In many applications, we can easily gather lots of data by placing microphones in a target environment and continuously listening and recording data. However, labeling this huge amount of data with the exact time boundaries of audio events is extremely difficult since:
- Annotating the large amount of audio data is very labor intensive.
- Human annotation is error-prone due to the ambiguity in the beginning and end time and short duration of some audio events.
One way to address the problem is labeling the audio data in a weakly manner in which time information of an event is not required. This way humans only label the type of an audio event, e.g., dog barking and does not indicate the start and end time of the event. Although this approach reduces labeling cost, it will introduce unrelated information to our model.
To address this issue, we may choose not to label any data and utilize unsupervised/self-supervised learning approaches to let the machine learning models extract hidden patterns in the unlabeled data. Unsupervised/self-supervised learning methods can be used on their own or as a feature extractor for other models.
Meanwhile, we can also label a small part of the data and utilize it to better fine-tune toward a downstream task. Other types of human knowledge, such as labels ontology structure, can also be injected to the system to boost the performance even further. Ontologies in computer science are usually linguistically formulated and formally ordered representations of a set of concepts and the relationships existing between them in a particular subject area
Below, we dive deeper into the approaches we took in each of these directions.
Unsupervised representation learning
In collaboration with University of Berkeley, we have designed a first of a kind unsupervised representation learning framework to learn discriminative features of audio events without the need for labels. We can further fine-tune the learned representation if we have access to a small amount of labeled data for our target task. In this approach the network attempts to classify each instance as a class in contrast to the traditional frameworks where multiple instances are grouped into single class.
We observed that the proposed approach accelerates network fine-tuning on the downstream task. Hence, we can train a general model to extract audio features and fine-tune it in very few epochs (3-5 epochs) to match the target task better. This is especially beneficial in an online learning setup on an edge device in which we have small computational resources available to train the model. In this scenario, it is important to improve the model performance on the edge over time through fine-tuning on new recorded data. The need of the edge computation might be initiated due to privacy concerns, avoid sending users’ audio data to the internet, or missing network availability.
For more technical details on this topic please check out our paper: Unsupervised Discriminative Learning of Sounds for Audio Event classification.
Applying ontology to sound classification
As discussed in the previous section, we can improve the unsupervised/self-supervised model performance by injecting human knowledge that is gained with minimal effort. This knowledge in its simplest form can be labeling a small amount of data and fine-tuning the model. We can also go a step further and incorporate the ontology structure of the abstract sound categories (labels) to the model. An ontology defines categories and relations between them. For example, figure 1 shows the ontology structure of “AudioSet”, one of the largest datasets in the field.
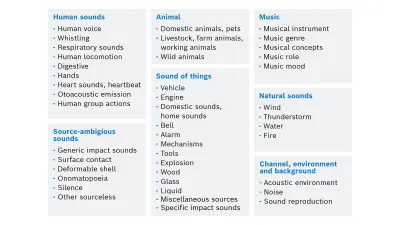
This structure is usually available as prior information in the form of common or general knowledge to human. Ontology represents the formal structure of classes or types of objects within a domain. As a result, ontology enables the models to process data in the context of what is known.
Semantic and context ontology
We focus on an end-to-end ontology-aware audio event classification model to capture the entities correlations in the ontology. More specifically, we define a task-independent and a task-dependent ontology structures to incorporate in our models:

This information is infused in the baseline audio event detection network via a graph convolutional neural network architecture and will refine the event detection. This helps the network to learn robust representations which can disambiguate audio classes that are acoustically similar but semantically different. It can also classify audio events in more general descriptors in case of ambiguity in sub-classes. Finally, in case of multi-label classification task, it incorporates the possibilities of events co-occurring in real world.
For more technical details on this topic please check out our papers: An Ontology-Aware Framework for Audio Event Classification.
Overall, our proposed frameworks will:
1) enable us to incorporate intuitive semantic and task related relationship between audio events to improve the classification performance;
2) leverage the available unlabeled audio data pool and reduce labeling cost; and
3) enable fast online learning on the edge devices.
These three benefits are specifically important for our Bosch use-cases:
- Given variety of business applications from smart home and campus to smart car, we collect data in different environments. Human often expect to hear certain sounds in each of these settings. For example, while collecting data in a street, it is more possible to hear car horn, music or children playing. On the other hand, inside a grocery store we expect to hear shopping cards, speaker announcements or can dropping. By injecting this intuitive knowledge to machine learning models, we can boost the performance.
- In many of the applications, we gather lots of unlabeled data by continuously listening to a target environment. Via unsupervised representation learning framework, we get information from this huge data. Meanwhile, we can label a small part of the data to better fine-tune toward a downstream task.
- User privacy is a topic taken seriously at Bosch. Collecting audio data continuously is privacy invasive in many places while some countries being more sensitive than others. In our frameworks, we emphasize on designing a system with the capability of running and updating on the edge device to avoid sending user’s information to the cloud.
What are your thoughts on this topic?
Please feel free to share them or to contact me directly.

Author: Shabnam Ghaffarzadegan
Shabnam is a researcher in the field of Audio Analytics. In her work, she incorporates acoustic signal processing and domain-specific machine learning methods to develop hearing sense for machines. Shabnam is part of Bosch SoundSee team located at Sunnyvale, CA and Pittsburg, PA, USA.
Google Scholar: Shabnam Ghaffarzadegan


