Introduction to knowledge-infused learning for autonomous driving
Bosch Research Blog | Post by Cory Henson, 2021-06-24


Co-author : Ruwan Wickramarachchi (AI Institute, University of South Carolina)
Autonomous driving is still far from being fully realized in scenarios requiring level 5 autonomy. Knowledge-infused learning—the integration of knowledge graphs and machine learning—can be the key to overcoming challenges in autonomous driving. An introduction.
Significant progress has been made in autonomous driving technology since it was first exhibited at the visionary DARPA Grand Challenge in 2004. Since that time, autonomous driving has been a key testbed for exploring the capabilities and limitations of machine learning. As driving requires comprehension of complex scenarios and the mapping of multimodal sensory inputs to control sequences, machine learning has proven quite effective at solving this challenge by approaching it as a non-linear control problem. Further, it has also shown great potential for generalization, as previously learned rules can often be applied to new driving scenarios, or new complex rules learned from experience. The rapid progress of machine learning for autonomous driving is further enabled by the recent availability and diversity of good datasets.
But even with these recent advancements, the technology is still far from ready to meet the requirements of full level 5 autonomy. The technical challenges of machine learning include, but are not limited to, safety, computation, architecture, verification and adaptability. In addition, fully autonomous driving and its widespread use pose new challenges, including user acceptance, accountability, explainability and conformance with legal, ethical, and societal boundaries.
As a potential solution to overcoming such challenges, we introduce the concept of knowledge-infused learning , which involves the integration of knowledge graphs with machine learning. We believe that intelligent integration of knowledge graphs will enrich the vehicle's understanding of complex driving situations, thus increasing its ability to deal with many technical and non-technical challenges.
In the following article, we’ll make the case for using knowledge graphs as the default data model for learning, and we’ll examine the synergies between knowledge graphs and machine learning to be achieved with knowledge-infused learning.
Knowledge graphs as the default data model for learning
Autonomous driving requires an advanced understanding of the vehicle’s situation in order to make informed decisions about how the vehicle should behave. Such an understanding is derived from observational data about the driving scene, which is provided in various modalities from disparate sources, including lidar, radar, cameras, and numerous other CAN bus signals (C ontroller A rea N etwork). The ability to fuse such information into a unified, coherent representation for robust decision-making is therefore a prerequisite for the sophisticated machine reasoning capabilities needed for autonomous driving.
Last year we introduced this topic by focusing on the pros and cons of knowledge graphs (symbolic knowledge) and machine learning (sub-symbolic knowledge).
“Symbolic and sub-symbolic methods are two classical techniques utilized in pursuit of such sense-making capabilities. Sub-symbolic, or data-driven, methods seek to model the statistical regularities of events by making observations in the real-world; yet they remain difficult to interpret and they lack mechanisms for naturally incorporating external knowledge. Conversely, symbolic, or knowledge-driven, methods combine structured knowledge graphs, perform symbolic reasoning based on axiomatic principles, and are more interpretable in their inferential processing. However, they often lack the ability to estimate the statistical salience of an inference. To combat these issues, we propose the use of a hybrid methodology as a general framework for combining the strengths of both approaches.” (Oltramari, 2020)
This approach is highly influenced by the thinking of Xander Wilcke of the Vrije University of Amsterdam. In 2017, Xander first proposed the adoption of knowledge graphs as the default data model for learning from heterogeneous knowledge.
“As long as we can assume that all relevant and irrelevant information is present in the input data, we can design deep [learning] models that build up intermediate representations to sift out relevant features. However, these models are often domain specific and tailored to the task at hand, and therefore unsuited for learning on heterogeneous knowledge: information of different types and from different domains.
To accomplish this, we first need a data model capable of expressing heterogeneous knowledge naturally in various domains, in as usable a form as possible, and satisfying as many use cases as possible. … [We] argue that the knowledge graph is a suitable candidate.” (Wilcke, 2017)
The effectiveness of Wilcke’s argument centers on the complementary strengths and weaknesses of knowledge graphs and machine learning, and the synergies derived through their integration.
- Seamlessly integrate heterogeneous information
- Search and update semantically annotated data at scale
- Re-use knowledge resources across datasets
- Logical reasoning
- Derive clear interpretations and explanations
Synergy through knowledge-infused learning
While machine learning has proven effective at solving many computational challenges, the full potential of machine intelligence is still far from being realized, as machine learning often falls short in dealing with problems such as interpretability, explainability, accountability, and lack of quality training data. Leveraging knowledge —including domain knowledge and commonsense knowledge that is often available as knowledge graphs, taxonomies, lexicons, and other symbolic representations —within sub-symbolic architectures could help machine learning overcome such challenges. The need for integrating machine learning/sub-symbolic representations with symbolic representations has been discussed for many years. In 2003, Leslie Valiant identified three problems in computer science, one of which is “characterizing a semantics for cognitive computation.”
Nearly two decades later, this is still an open problem. However, a novel idea has emerged in AI “neuro-symbolic computing/knowledge-infused learning,” which aims to achieve Valiant’s vision —intelligent cognitive behavior —by learning from experience and reasoning from what has been learned. In broad terms, the knowledge in neuro-symbolic computing is represented in symbolic forms, while learning, reasoning, and inferencing are achieved using neural networks. However, as Sheth et al. point out, this will require resolving the “impedance mismatch” due to the differences in representation and abstraction between symbolic and sub-symbolic systems.
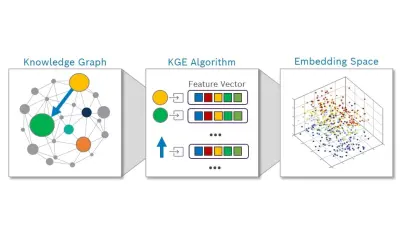
Recently, there has been an uptick in techniques attempting to bridge the symbolic/sub-symbolic divide. Sheth et al. categorize this recent work as a continuum of shallow, semi-deep and deep infusion of knowledge. Of the recent methods, Knowledge Graph Embeddings (KGEs) remain the most widely adopted approach for representing the knowledge in KGs and integrating them with machine learning architectures. KGEs transform entities and relations in the KG into vectors/matrices in the continuous vector space, allowing them to be consumed by other sub-symbolic methods. While this transformation is not lossless, many KGE approaches have recently been proposed to limit the transition loss by explicitly exploiting semantics such as type and hierarchy information. Even at their current stage of development, KGEs show excellent potential for achieving the aims of knowledge-infused learning, particularly explainability, compared to their current machine learning counterparts.
Conclusion
In summary, over the next few years we anticipate exciting new research into hybrid AI systems and technologies, such as knowledge-infused learning, that will be able to seamlessly integrate and unify machine learning and knowledge graphs. This technology holds enormous promise and potential to overcome some of the challenges facing autonomous driving.
What are your thoughts on this topic?
Please feel free to share them via LinkedIn or to contact me directly.
Author: Cory Henson
Cory is a lead research scientist at Bosch Research and Technology Center with a focus on applying knowledge representation and semantic technology to enable autonomous driving. He also holds an Adjunct Faculty position at Wright State University. Prior to joining Bosch, he earned a PhD in Computer Science from WSU, where he worked at the Kno.e.sis Center applying semantic technologies to represent and manage sensor data on the Web.

Co-author : Ruwan Wickramarachchi
Affiliation : AI Institute, University of South Carolina


