Six grand opportunities from knowledge-infused learning for autonomous driving
Bosch Research Blog | Post by Cory Henson, 2021-07-06


Co-author : Ruwan Wickramarachchi (AI Institute, University of South Carolina)
Using knowledge-infused learning to integrate knowledge graphs and machine learning can lead to improvements in autonomous driving. Here are six grand opportunities at the cutting edge of this exciting new research field.
Combining the strengths of knowledge graphs with machine learning is a promising approach to advancing autonomous driving technology. We’d like to briefly discuss six grand opportunities enabled by knowledge-infused learning that the research community is now beginning to investigate.
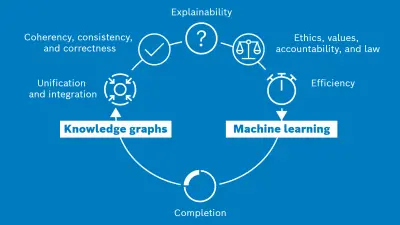
#1: Unification and integration
The number and variety of data, especially sensor data, generated by autonomous vehicles has grown dramatically in the last few years, including lidar, radar, and CAN bus signals (Controller Area Network). To transform this enormous amount of heterogeneous, multi-modal data into a unified representation with actionable knowledge of a driving scene, we must first solve the fundamental problem of data/knowledge integration. Integration is often considered the primary benefit of knowledge graphs, where combining datasets is as simple as linking two graphs with equivalent resource identifiers (i.e. IRIs). Advances in knowledge graph technology could be a huge step toward a unified representation and understanding of driving scenes.
Learn more: The knowledge graph as the default data model for learning from heterogeneous knowledge
#2: Completion
Knowledge graphs are rarely complete, as they are always changing and evolving. Knowledge graph completion is the act of inferring—or learning—new facts in a knowledge graph based on the existing relational data. Also referred to as link prediction, this process boils down to predicting new links between entities in the graph. For the autonomous driving domain, this may include predicting links associated with a scene, such as location, or predicting links between entities in the scene, e.g. inferring that a traffic light has caused vehicles to stop.
Over the past few years, knowledge-infused learning (in general) and knowledge graph embeddings (more specifically) have become a primary tool for enabling knowledge graph completion. With this approach, KG embeddings are used to train a machine learning model capable of predicting new links with high accuracy. Because of its clear importance and utility, link prediction has become the de facto task used to evaluate and benchmark new KG embedding algorithms.
Learn more: Knowledge Graph Embedding: A Survey of Approaches and Applications
#3: Coherency, consistency, and correctness
With highly automated systems such as autonomous vehicles that rely heavily on data for critical decision making, the correctness, consistency, and coherence of the data is paramount. Knowledge graphs and knowledge-infused learning can play a key role in ensuring our data is trustworthy. Tran et al. best made the case for using knowledge graphs to ensure the coherency, consistency, and correctness of data and knowledge.
“As knowledge graphs are often automatically constructed, through error-prone methods such as information extraction, crowd-sourcing, or KG embeddings, they may contain incorrect, inconsistent, or incoherent facts. For example, this may include incorrectly disambiguated entities or faulty nd-relations. Detecting them is a crucial, yet extremely expensive task. Prominent solutions detect and explain inconsistency in KGs with respect to accompanying ontologies that describe the KG domain of interest with formal, logical representation. Compared to machine learning methods they are more reliable and human-interpretable but scale poorly on large KGs.”
#4: Efficiency
The effectiveness of machine learning methods strongly depends on data efficiency. Specifically, when the data is sparse and/or imbalanced, models tend to suffer from under-representation issues, which lead to poor generalization and poor performance. To cope with this, the machine learning models used in the autonomous driving domain attempt to generate additional training data using either random, statistical or heuristic-based approaches. Employing knowledge graphs within this process could help augment the training data with the known facts in the knowledge graph, resulting in better-quality positive and negative examples. Additionally, machine learning often suffers from training data unavailability of unseen classes that seriously limits its usage in open-world situations often encountered while driving. For example, encountering a fallen tree on the road might not be something an autonomous car has ever observed in the training data. However, having access to knowledge graphs—especially commonsense knowledge graphs such as ConceptNet—could help machine learning overcome challenges encountered in open world driving situations such as data sparsity and gaps in training data.
Learn more: Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web
#5: Explainability
Explainability is one of the primary concerns of AI applications, since machine learning models often lack transparency and do not provide explanations of their behavior. While explainability may be defined differently in different contexts, Freddy Lecue identifies explainability as “intelligent systems able to expose explanations in a human comprehensible way”. While traditional machine learning methods such as decision trees are better at offering explanations, methods focused on neural networks require explicit modeling of feature importance (e.g. attention mechanisms, surrogate models) to provide explanations, which are weak even in the best case. For this reason, safety critical applications such as autonomous driving that heavily rely on machine learning require new and novel frameworks that are better at explaining their decisions. When knowledge graphs are used alongside machine learning, the components of machine learning—inputs, outputs and the relationships among them (as learned by the neural model) —can be mapped onto known artifacts in the knowledge graph, allowing people (and semantic reasoners) to derive logical and understandable explanations.
Learn more: On the Role of Knowledge Graphs in Explainable AI
#6: Ethics, values, accountability, and law
Realizing the vision of full level 5 autonomy goes beyond safely maneuvering the vehicle from one point to another. It also involves constantly making decisions that affect other humans and vehicles on the road, conforming to traffic laws and regulations, adhering to societal norms and values, and successfully dealing with ethical dilemmas. The knowledge about law, ethics, values and social norms, gathered over centuries of effort, are available in symbolic representations and are followed by people making decisions every day. We believe learning these subtle values entirely from low-level training is ineffective and error prone. Hence, we suggest that there is a unique opportunity here to “infuse” this hard-won knowledge with the machine learning used in autonomous driving to gain insights that are invaluable for robust decision making on the road. Further, this will improve accountability by allowing AI models to be thoroughly regulated and investigated according to current rules, laws and norms.
Learn more: On the problem of making autonomous vehicles conform to traffic law
What are your thoughts on this topic?
Please feel free to share them via LinkedIn or to contact me directly.
Author: Cory Henson
Cory is a lead research scientist at Bosch Research and Technology Center with a focus on applying knowledge representation and semantic technology to enable autonomous driving. He also holds an Adjunct Faculty position at Wright State University. Prior to joining Bosch, he earned a PhD in Computer Science from WSU, where he worked at the Kno.e.sis Center applying semantic technologies to represent and manage sensor data on the Web.

Co-author : Ruwan Wickramarachchi
Affiliation : AI Institute, University of South Carolina


